HI,這是演算法挑戰挑戰的第二篇,我這個人習慣有求必應,所以這篇就來解解SQL的題目吧!
題目名稱:Department Highest Salary
難易度:中
題目內容:從Employee和Department兩張資料表中查詢出各部門領最高薪水的人及金額。
例如:Employee表內容:
| Id | Name | Salary | DepartmentId |
|---|---|---|---|
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
Department表內容: |
|||
| Id | Name | ||
| ------------- | ------------- | ||
| 1 | IT | ||
| 2 | Sales | ||
| 查詢結果: | |||
| Department | Employee | Salary | |
| ------------- | ------------- | ------------- | |
| IT | Max | 90000 | |
| Sales | Henry | 80000 | |
| 那以下開始動工: |
/*SELECT資料欄位*/
SELECT d.Name AS Department ,e.Name Employee ,s.salary
/*以部門為主檔*/
FROM Department d
LEFT JOIN
/*找出各部門的最高薪水*/
(SELECT MAX(Salary) Salary ,DepartmentId
FROM Employee
GROUP BY DepartmentId) s
/*用部門編號取得部門名稱*/
ON s.DepartmentId = d.Id
/*連結員工資料表*/
LEFT JOIN Employee e
/*用在哪個部門,以及該最高薪水找出對應的人名*/
ON e.DepartmentId = s.DepartmentId AND e.Salary=s.Salary
/*如果有該部門但沒有人員會回傳NULL,所以這時候把他過濾掉*/
WHERE s.salary IS NOT NULL
嘛...雖然我是用這個方式串出來了,但是其實我在下SQL的時候除非跑得特別慢,不然我都不會去注意到效能的問題,也沒有認真研究過怎麼處理資料會比較好,只想著最後出現是我要的就好,如果出現不了再從程式下手 ,所以我在SQL解題的時候通常都會硬湊,如果看到我的解題方式,有哪裡可以改進的,再麻煩各位大大留言告訴我,我會在今後的寫法一一嘗試的
,所以我在SQL解題的時候通常都會硬湊,如果看到我的解題方式,有哪裡可以改進的,再麻煩各位大大留言告訴我,我會在今後的寫法一一嘗試的
另外如果寫法有誤或有什麼問題,也都可以告訴我,我在盡速修正,謝謝大家!
晚上試作了一下,
我的解法也跟你一樣...
哈哈哈,我們都一樣,英雄所見略同
我下SQL時也不會特別注意效能問題,原因是因為專案型的案子業務接進來時,DB都已經不知道經過幾手了,資料本身有些就很悲劇了,能撈出PM要的資料就"阿彌陀佛"了!所以公司才要導入Spark來整理來自各廠DB的資料!
哈哈,真的欸!
其實只要資料不要跑得很久,我都不會特別去注意到哪種寫法比較好,而且現在有分頁語法,就算效能差也不會一次查很多筆資料,除非是報表
哈哈哈,我也一樣!!
DECLARE @Employee TABLE
(
Id INT,
Name NVARCHAR(50),
Salary INT,
DepartmentId INT
);
DECLARE @Department TABLE
(
Id INT,
Name NVARCHAR(50)
);
INSERT INTO @Employee
(Id, Name, Salary, DepartmentId)
VALUES
(1, N'Joe', 70000, 1),
(2, N'Henry', 80000, 2),
(3, N'Sam', 60000, 2),
(4, N'Max', 90000, 1)
INSERT INTO @Department
(Id, Name)
VALUES
(1, N'IT'),
(2, N'Sales')
SELECT C.Name,
A.Name,
A.Salary
FROM @Employee AS A
LEFT JOIN (
SELECT A.DepartmentId,
MAX(A.Salary) AS Salary
FROM @Employee AS A
GROUP BY A.DepartmentId
) AS B ON B.DepartmentId=A.DepartmentId AND B.Salary=A.Salary
LEFT JOIN @Department AS C ON C.Id=A.DepartmentId
WHERE B.Salary IS NOT NULL
ORDER BY A.DepartmentId
一種工程師的默契,只是主表反過來了,哈哈哈XD
下篇的這個系列我去翻翻看有沒有我覺得很酷的解法分享好了
恩~~我也玩玩了@@~
declare @Employee table(
Id int
,Name nvarchar(50)
,Salary int
,DepartmentId int
)
insert into @Employee
values(1, N'Joe', 70000, 1),(2, N'Henry', 80000, 2),(3, N'Sam', 60000, 2),(4, N'Max', 90000, 1)
declare @Department table(
Id int
,Name nvarchar(50)
)
insert into @Department
values(1, N'IT'),(2, N'Sales')
select Name,Salary
from (
select Row_Number() Over(Partition by a.Id Order by b.Salary desc) as Sort
,a.Name
,b.Salary
from @Department as a
left join @Employee as b on a.Id = b.DepartmentId
) as k
where Sort = 1
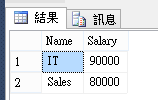
第二種...像這樣吧
select a.Name
,isNull((
select top 1 Salary
from @Employee as b
where a.Id = b.DepartmentId
order by Salary desc
),0) as Salary
from @Department as a
這樣也行..
select a.Name
,isNull((
select max(Salary)
from @Employee as b
where a.Id = b.DepartmentId
),0) as Salary
from @Department as a
如果是T-SQL寫法的話~應該是這樣吧XD..
declare @Detail table(
Department_Name nvarchar(50)
,Employee_Name nvarchar(50)
,Salary int
)
declare @i int,@Max int
declare @Index int,@Department_Name nvarchar(50)
declare @Employee_Name nvarchar(50),@Salary int
set @i = 1
select @Max = isNull(count(*),0)
from @Department
while(@i<=@Max)
begin
select @Index=Id
,@Department_Name=Name
from (
select Row_Number() Over(order by Id) as Sort
,Id
,Name
from @Department
) as k
where Sort = @i
select top 1
@Employee_Name=Name
,@Salary=Salary
from @Employee
where DepartmentId = @Index
order by Salary desc
insert into @Detail
values(@Department_Name,@Employee_Name,@Salary)
set @Employee_Name = ''
set @Salary = 0
set @i = @i +1
end
select * from @Detail
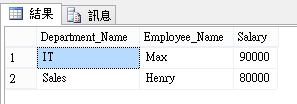
這個我參考darwin0616分享的方式改寫的~也是可以用這方式@@...
SELECT
b.Name AS 'Department',
a.Name AS 'Employee',
Salary
FROM
@Employee as a
JOIN
@Department as b ON a.DepartmentId = b.Id
WHERE
exists(
select *
from @Employee as c
where c.DepartmentId = b.Id
having MAX(c.Salary) = a.Salary
)
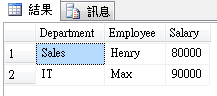
哦!有不同的方式了!
先做分組查詢,在把編號為1的資料撈出來,
不曉得還能不能看到其他解法
恩..再多弄了一種...@@a
可是這會不會還必須再另外寫一個子查詢才能找出員工姓名
嗯~的確有2個欄位以上~子查詢不適合~
還是我原來那個查詢是可以帶多個欄位顯示
多玩了一個比較麻煩寫法@@~
用T-SQL的方式來寫..
其實我不太曉得T-SQL和一般的SQL有什麼不一樣
是指用類似程式的處理方式嗎?
對~可以用程式方式的寫法~
你可以看維基的介紹
https://zh.wikipedia.org/wiki/Transact-SQL
哈哈哈,感謝大大
如果會T-SQL應該就可以自己寫很多的預存函式和可程式性來使用了,可惜我還無法
這個我參考darwin0616分享的方式改寫的~
也是可以用這Exists方式@@...
哇哇,到T-SQL的領域內我就完全看不懂了,感覺大大很專精SQL這方面,是工作中常常接觸到複雜的資料處理訓練出來的嗎
@@..基本算是全方位工程師啦...系統架設、程式開發、美工製作都自己來..
在台南一間小補習班...
老闆想做什麼報表分析~是這樣練出來的~求查資料快~不斷的改良SQL..
我也在台南耶!!!!這世界有夠小的
哈哈..
遇見同鄉人太興奮了,哈哈哈,
不過連美工製作都自己來也太...
用Postgresql 來玩玩
create table dept (
id int not null primary key
, name text not null
);
create table emp (
id int not null primary key
, name text not null
, salary int not null
, dept_id int not null references dept(id)
);
insert into dept values
(1, 'IT'), (2, 'Sales');
insert into emp values
(1, 'Joe', 70000, 1),
(2, 'Henry', 80000, 2),
(3, 'Sam', 60000, 2),
(4, 'Max', 90000, 1);
--
select dept_id
, first(name order by salary desc)
, first(salary order by salary desc)
from emp
group by dept_id;
dept_id | first | first
---------+-------+-------
1 | Max | 90000
2 | Henry | 80000
(2 筆資料列)
select d.name Department
, a.employee
, a.salary
from (select dept_id
, first(name order by salary desc) employee
, first(salary order by salary desc) salary
from emp
group by dept_id) a
join dept d
on a.dept_id = d.id;
department | employee | salary
------------+----------+--------
IT | Max | 90000
Sales | Henry | 80000
(2 筆資料列)
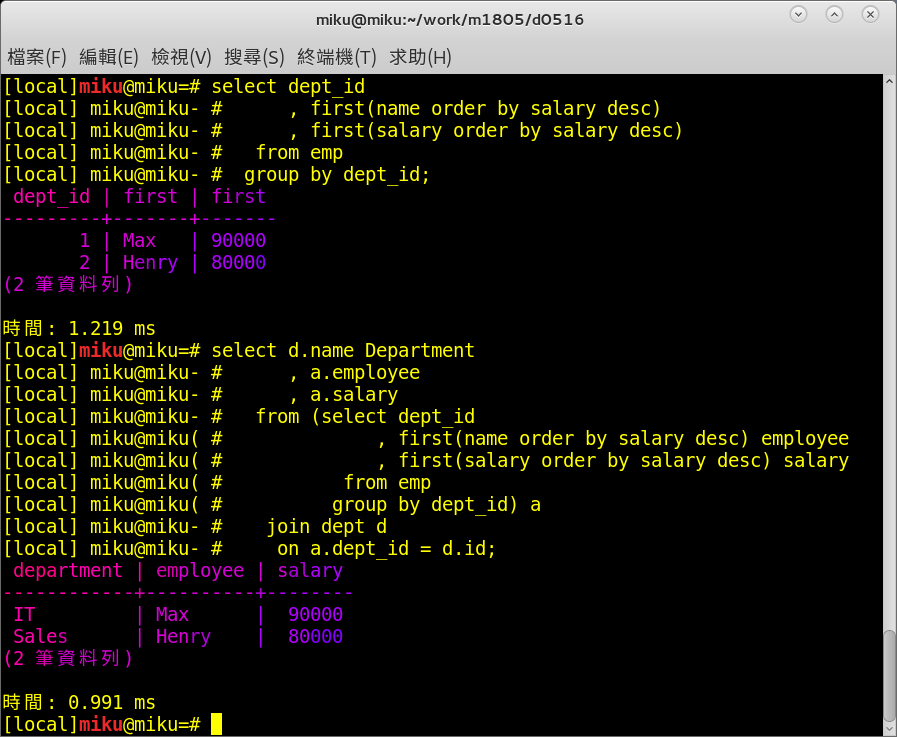
哇,IT邦果然高手雲集,哈哈哈,first(salary order by salary desc)
這是類似MSSQL的TOP 1,不過可以只針對一個欄位做排序我覺得還滿厲害的,而且靈活度大大提升
不是只針對一個欄位作排序.....這個你誤會了. top 1 跟這完全不同.
你仔細看我的例子,第1道SQL已經解答出來了,後面只是要取dept的name而已.
不好意思,因為一直沒實際使用過Postgresql,所以以下兩行不能畫上等號ㄛ
first(salary order by salary desc)
(SELECT TOP 1 salary ORDER BY salary DESC)
剛剛稍微查了一下fisrt()回傳數組內第一個資料,感覺有點像但是不知道差異在哪裡
重點在 first(name order by salary desc)
所以first(name order by salary desc)會影響到後面的那一行結果嗎?first(salary order by salary desc)
這是函數,不是subquery.
哈哈,只是這個函數執行出來的結果好像子查詢
就是結果能一樣,就不必subquery self join.
感謝大大耐心解釋,如果今後用到Postgresql就可以不用在SELECT內放一堆子查詢了
解法跟樓主差不多...... (我用MariaDB)
CREATE TABLE IF NOT EXISTS `Employee` (
Id INT(8) NOT NULL AUTO_INCREMENT,
Name VARCHAR(52) NOT NULL,
Salary INT(8) NOT NULL,
DepartmentId INT(8) NOT NULL,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE IF NOT EXISTS `Department` (
Id INT(8) NOT NULL AUTO_INCREMENT,
Name VARCHAR(52) NOT NULL,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `Employee`
(Name, Salary, DepartmentId) VALUES
('Joe', 70000, 1),
('Henry', 80000, 2),
('Sam', 60000, 2),
('Max', 90000, 1);
INSERT INTO `Department` (Name) VALUES ('IT'), ('Sales');
SELECT d.Name AS Department, e.Name AS Employee, e.Salary AS Salary FROM `Employee` AS e
RIGHT JOIN (
SELECT MAX(Salary) AS MaxSalary, DepartmentId AS DepId
FROM `Employee`
GROUP BY DepartmentId
) AS m ON e.Salary = m.MaxSalary AND e.DepartmentId = m.DepId
JOIN `Department` AS d ON e.DepartmentId = d.Id
ORDER BY Salary ASC;
第一次看到MariaDB,不過看起來和MYSQL很像
這個解法和二樓的fysh711426大大一樣,話說難道把DepartmentId部門檔當做主檔的我是異類嗎?哈哈哈。
我 ... ... 直接貼網站的解答公佈官方答案 ... ...
SELECT
Department.name AS 'Department',
Employee.name AS 'Employee',
Salary
FROM
Employee
JOIN
Department ON Employee.DepartmentId = Department.Id
WHERE
(Employee.DepartmentId , Salary) IN
( SELECT
DepartmentId, MAX(Salary)
FROM
Employee
GROUP BY DepartmentId
)
;
條件裡的這一段是我近期才看到的語法,就是一次對多個欄位使用IN語句,不過MSSQL好像無法用這種寫法,讓我非常羨慕MYSQL
(Employee.DepartmentId , Salary) IN
( SELECT
DepartmentId, MAX(Salary)
FROM
Employee
GROUP BY DepartmentId
)
我是用MySQL 想問一下
select d.Name Department,e.Name Employee,MAX(e.Salary) Salary from employee e inner join department d on e.DepartmentId = d.Id GROUP BY e.DepartmentId
輸出的結果跟答案一樣為什麼還是錯誤的回答
我還是新手學生@@
痾 我找到錯誤了 輸出的人不同 不好意思QQ
哈哈,不會啦,
在程式面前人人平等XD
歡迎你每個禮拜如果有題目都來分享做法!
另外,你目前寫法只能帶出這個部門最高薪水,
還要想想辦法才能把該部門領該薪水的人名帶出來,加油啊!
 神Q超人
神Q超人
